
Amazon S3 (Simple Storage Service), es un servicio de almacenamiento en la nube escalable, con alta disponibilidad, con la posibilidad de manejar un costo según del patrón y frecuencia de uso de los datos, con cifrado de los archivos, y un control de acceso seguro a los recursos.

Una de las medidas de gran relevancia para la recuperación de un sistema ante fallas graves, lo constituye el backup periódico, tanto de sus bases de datos, como de otro tipo de archivos recolectados durante su operación.
En sistemas que manejan grandes volúmenes de datos y archivos multimedia, se hace necesario que los backups no solo estén ubicados en la máquina de origen, sino que puedan ser trasladados a otras ubicaciones, de tal forma que se pueda recuperar el sistema aun en el caso de una falla catastrófica.
Es así como Amazon S3 es una herramienta, que junto con los servicios de Amazon EC2, permiten el almacenamiento de grandes volumenes de datos, en diferentes clases de almacenamiento y ciclos de vida, con costos adecuados a dichas características.
Clases de almacenamiento en Amazon S3
Las clases de almacenamiento que maneja Amazon S3 son:
- Estándar,
- Capas inteligentes,
- Estándar – Acceso poco frecuente (IA),
- Unica Zona – Acceso poco frecuente (Zone IA),
- Glacier, Archivo profundo de Amazon S3 Glacier y
- S3 Outposts.
Cada una de estas opciones está pensada en la frecuencia de acceso a los datos y su localización geográfica. De tal modo que se obtiene un menor costo, entre menos frecuencia de acceso se tenga a los datos almacenados. Los costos asociados a cada una de estas opciones se puede encontrar con mayor detalle en esta página oficial de Amazon AWS https://aws.amazon.com/es/s3/pricing/?nc=sn&loc=4 , o por medio de la calculadora de servicios de Amazon Calulator AWS.
Amazon EC2 y Amazon S3
Una de las ventajas de almacenar los backups de la infraestructura de Amazon EC2 en S3, es que la transferencia de datos entre el servidor origen y S3 es gratuita, siempre y cuando ambos sistemas estén en la misma zona de Amazon AWS.
Los archivos provenientes de Amazon EC2 se pueden copiar a Amazon S3, o se pueden sincronizar para evitar la transferencia innecesaria de archivos sin cambios.
Cómo se transfiere un backup desde EC2 a Amazon S3
Considerando que contamos con un servidor EC2 en linux, los siguientes son los pasos para gestionar y transferir un backup a S3:
- Se instala la consola aws en la máquina linux, mediante el siguiente comando:
curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip"unzip awscli-bundle.zipsudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws
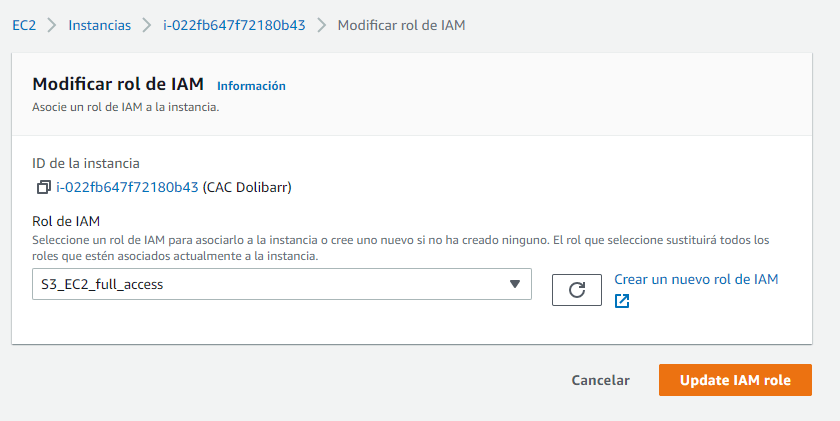
- Se crea un rol en IAM, con policies de acceso full de EC2 a S3. El procedimiento detallado para dar acceso se puede seguir en el artículo: Writing IAM Policies: How to Grant Access to an Amazon Bucket.
- El Rol se puede usar en una instancia nueva o ya creada de Amazon EC2, así se puede registrar el rol para una instancia existente:
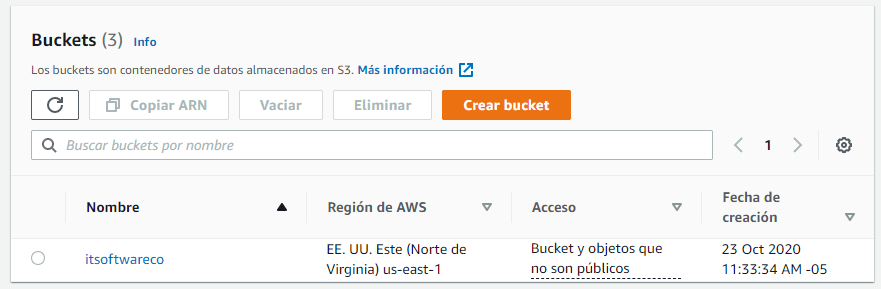
- Se crea un bucket, por ejemplo itsoftwareco. Por defecto este bucket no es público.
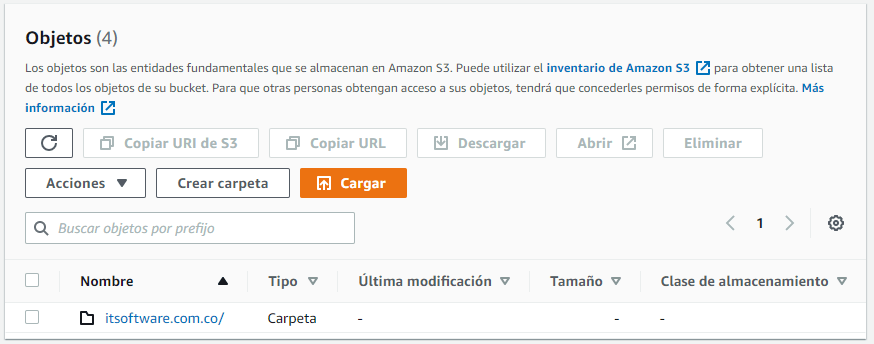
- Dentro de este bucket se pueden crear carpetas para organizar la información, por ejemplo itsoftware.com.co.
- Ahora se transfiere el archivo de backup, mediante algún script periódico, por ejemplo 1 vez cada 8 días, mediante el siguiente comando si es para copia:
aws s3 cp ~/code/backup/ s3://itsoftwareco/itsoftware.com.co --recursive --exclude "*" --include "mibackup_*"
O éste si es para sincronización:
aws s3 sync ~/code/backup/ s3://itsoftwareco/itsoftware.com.co --exclude "" --include "mibackup"
Los archivos son almacenados de forma predeterminada como clase de almacenamiento Estándar. Este tipo de almacenamiento se puede cambiar automáticamente luego de un tiempo o de forma manual.
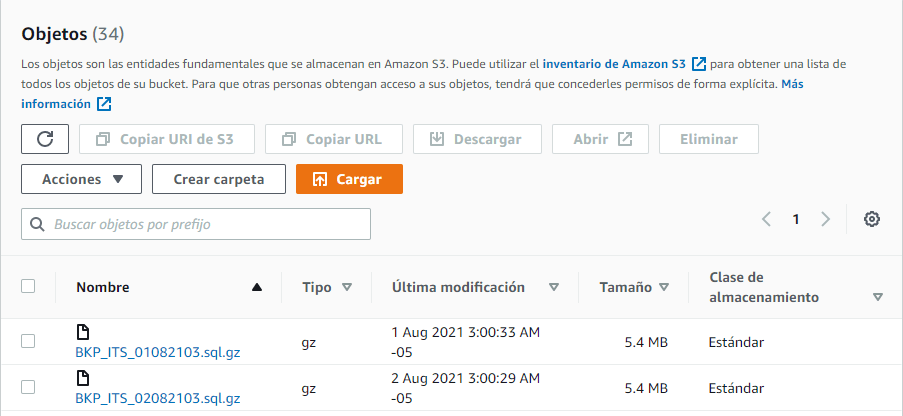
Cambio de tipo de almacenamiento manualmente
Para realizar esta acción, se escoge el directorio, archivo o archivos que se desean modificar, luego con el botón Acciones, seleccionamos Editar clase de almacenamiento, apareciendo las diferentes opciones, y los requisitos de tiempo, y zonas de disponibilidad para cada uno de ellos:
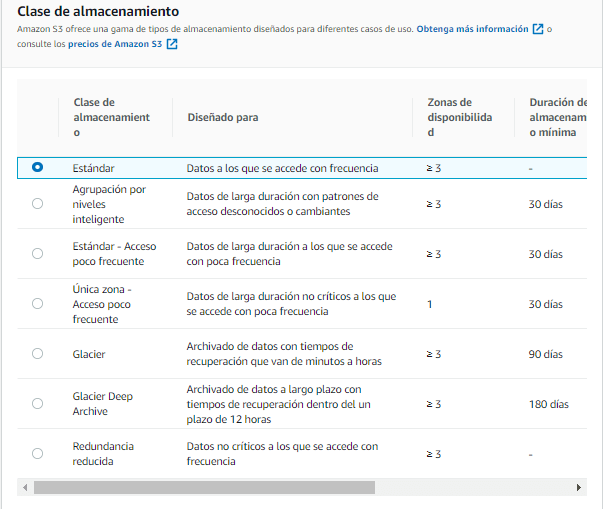
Al final se presiona el botón Guardar Cambios, para aplicar las modificaciones realizadas.
Se debe considerar que un cambio de estado de almacenamiento, antes de que pase el tiempo mínimo de permanencia en el estado actual, ocasiona un costo adicional.
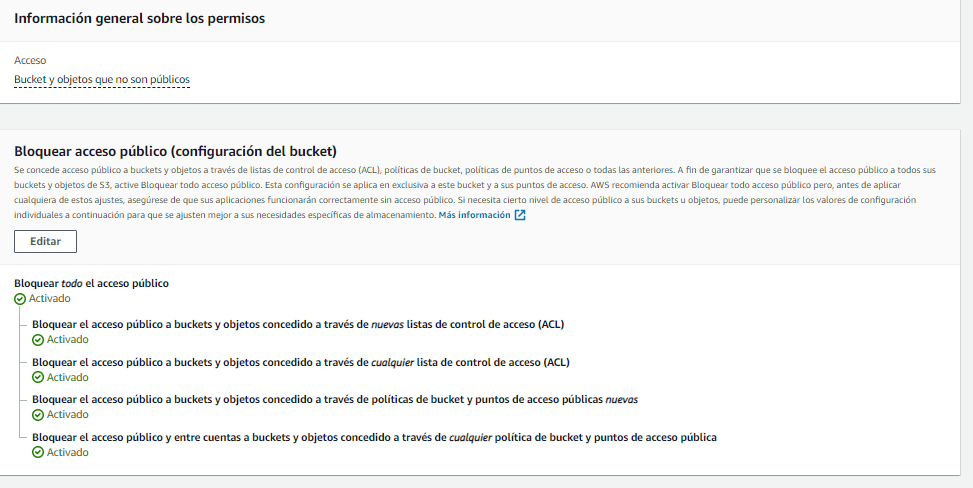
Permisos del bucket
A cada bucket se le asignan permisos, para que pueda ser público o solo accesible mediante una lista o una política del bucket en json.
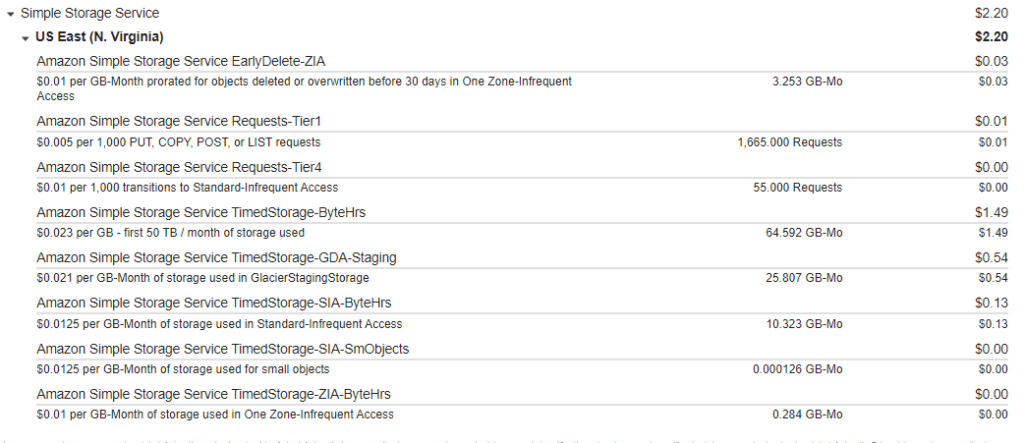
Ciclo de vida de los backups
Mediante esta opción, a todos los archivos de un bucket se le puede aplicar una política de retención y borrado de datos, transfiriéndolos a las diferentes clases de almacenamiento, para aprovechar el menor costo y también tener los archivos antiguos por un tiempo predeterminado, y evitar así un excesivo tamaño del bucket.
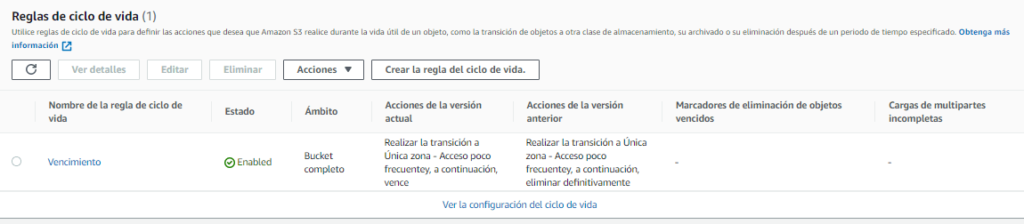
Métricas de buckets Amazon S3
La pestaña de métricas de bucket, muestra un resumen del tamaño y cantidad de objetos, en cada una de sus clases de almacenamiento.
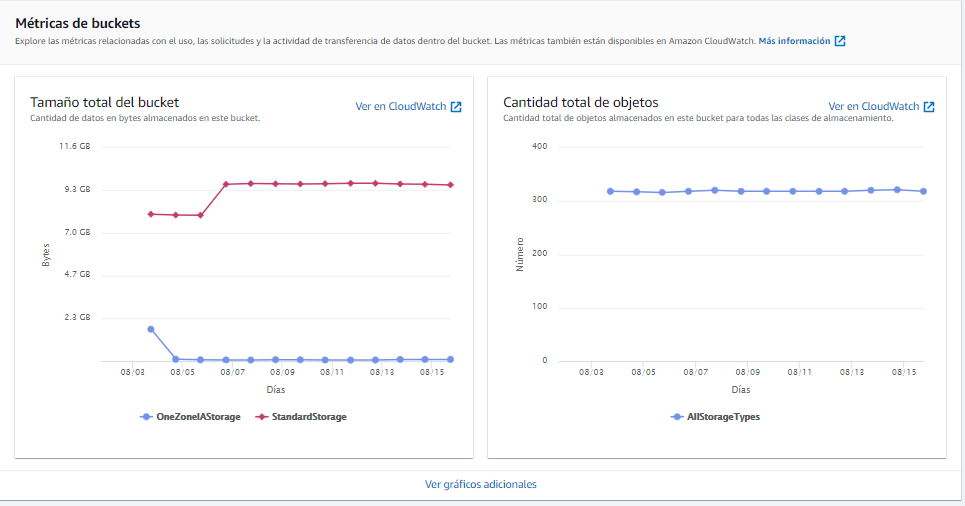
Facturación Amazon S3
La facturación del servicio Amazon S3 se efectúa según las clases del servicio, y se muestra de forma detallada en el panel de facturación de la cuenta Amazon AWS.
Como conclusión, Amazon S3 es un servicio de gestión de almacenamiento, escalable, flexible y de costo adaptable a las necesidades de cada administración de IT, para mantener al día y en un lugar seguro, los backups que periódicamente se realizan a la infraestructura de servidores.
Este artículo hace parte del sistema de divulgación de conocimiento de ITSoftware SAS.